<Abstract>
-대규모 인식 환경에서 합성곱 신경망의 깊이가 정확도에 미치는 영향에 대해서 조사.
-3x3의 합성곱 필터를 사용(나중에 나오겠지만 상하좌우, 가운데의 개념이 있는 가장 작은 단위임)
-깊이가 16~19일 때 최고 성능이 크게 개선.
-다른 데이터셋에도 일반화가 잘됨.
1. Introduction
-최근 대규모 이미지 저장소, GPU, 대규모 분산클라스터 등의 고성능 컴퓨팅 자원이 생겨나면서 ConvNets가 도움을 받음.
-ILSVRC 대회는 이미지 분류에 대한 테스트를 하기에 굉장히 좋음.
-컴퓨터 비전 분야에서 ConvNets가 많이 사용되기 시작.
-ConvNets은 2010년대부터 합성곱 계층의 창 크기와 보폭 등 개선방향이 있었으나, 위 논문에서는 '깊이'에 초점을 둠.
-3x3 합성곱 필터로 '깊이'를 증가 시키는 것.
2. ConvNet Configurations
-깊이가 증가함으로써의 개선을 공정한 환경에서 측정해야함으로 모든 ConvNet 층 구성을 동일한 원칙에 따라 설계
2-1. Architecture
-224 x 224 x 3(RGB)의 데이터에 가하는 유일한 전처리는 훈련세트에서 계산된 평균 RGB값을 각 픽셀에서 빼는 것.
-상하좌우, 중심의 개념을 가지는 가장 작은 필터인 3 x 3 필터를 사용.
-입력채널의 선형변환이라고도 볼 수 있는 1 x 1의 conv 필터도 사용(비선형성이 뒤따름) **
-이 때, 스트라이드는 1 픽셀로 고정되어 있으며, 패딩은 conv 연산 후에 공간 해상도가 보존이 되도록 함.
-공간풀링은 conv레이어를 따르는 MAX 풀링을 수행.(전부가 MAX 풀링은 아님.)
-MAX 풀링은 2 x 2 픽셀로 스트라이드 2를 적용하여 수행.
-Conv 연산과 풀링 연산을 끝내면 세 개의 Fully Connected layer가 이어짐.
-첫 번째와 두 번째 FC layer는 4096개의 채널을 가지고 있고, 세 번째는 1000개의 채널을 가지고 있음.
-1000개의 클래스 각각에 대한 출력을 수행하여 최종 소프트맥스 레이어로 출력됨.
-모든 히든 레이어는 활성화 함수로 ReLU를 사용
-네트워크 중 하나를 제외하고는 어떤 네트워크도 Local Response Normalisation 정규화를 포함하지 않는다. **
2-2. Configurations
-네트워크 (A-E)는 일반적인 디자인을 따르며 깊이만 다름.
-ex) A(8개의 conv레이어와 3개의 FC레이어)는 11개의 가중치 레이어 E(16개의 conv 레이어, 3개의 FC레이어)는 19개의 가중치 레이어
-conv 레이어의 채널 수는 64부터 시작하여 MAX 풀링 이후에 2배씩 증가하여 512에 도달함.
-더 큰 conv 레이어 너비와 수용영역을 갖는 얕은 네트워크(A)와 비교하여 큰 깊이에도 불구하고 (C,D,E) 그렇게 차이 나지는 않음. **

2-3. Discussion
-이 논문이 나오기 전 이미지 분석 대회에서 가장 성능이 좋았던 모델들은 convnet의 구성에서 첫 레이어가 11 x 11 필터에 스트라이드 4를 사용하는 등 매우 큰 수용 영역을 사용했으나, VGG는 3 x 3이라는 가장 작은 영역을 사용함.
-첫 번째 장점: 3 x 3을 여러번 사용함으로써 여러개의 비선형적인 정사각 함수를 포함시켜 더 구별적인 결정함수를 만듦,
-두 번째 장점: 3 x 3을 3번 사용한다 쳤을 때, 매개변수는 27^2개가 필요하지만, 단일 7 x 7은 49C^2개가 필요하므로 매개변수를 줄임.
-1 x 1 conv가 들어가는 것은 그저 선형 투영일 뿐 인데, 정사각 함수에 의해 추가적인 비선형성이 주입됨. **
-여러 연구에서 깊이의 증가가 더 나은 성능의 상승을 이끌었음.
3. Classification Framework
-이번 섹션에서는 분류 ConvNet의 훈련 및 평가의 세부 사항을 설명.
3-1. Training
-미니배치(배치 크기는 256, 모멘텀은 0.9) 경사 하강법을 사용하여 훈련이 진행됨. 가중치 감쇠와, 드롭아웃 비율 0.5 설정.
-초기 학습률은 10^-2엿으나, 정확도 상승에 정체가 보일 때 10으로 나누어 더 감소시킴. 총 3번의 감소가 이루어짐.
-370k 반복(74 에폭) 후에 중지. 에폭이 적은 이유는 1.깊고, 작은 conv 레이어 2. 특정 레이어의 사전 초기화. **
-224 x 224 크기로 맨날 이미지를 입력 받기 위해, 조금 더 큰 높이와 너비를 가진 데이터가 들어오면 임의로 데이터가 잘리는 현상이 있음.
-훈련 세트를 증가시키기 위해서 수평뒤집기 등의 데이터 augment가 있었음.
-데이터가 잘리면서 크기가 조정되는 가장 작은 측면을 s라고 정의했을 때 s = 224인 경우에는, 자른 후 그대로 사용, 224보다 큰 경우에는 작은 객체나 객체의 일부를 포함할 것.(오버피팅을 방지하는 데 도움이 될 것.)
-s를 설정 하는 방법은 두가지(단일 스케일 훈련, 다중 스케일 훈련)
-s를 고정하는 것은 크기를 고정하여 네트워크를 훈련시킴, 다중 스케일 훈련은 s를 고정하지 않고 범위를 설정하여, 랜덤하게 샘플링 함.
-다중 스케일 훈련은 이미지의 크기가 다양할 수 있으므로 이를 잘 고려햐야 함.
3-2. Testing
-FC 레이어가 먼저 Conv layer로 변환됨.(첫 번째 FC 레이어는 7 x 7 conv 레이어, 마지막 두 FC 레이어는 1 x 1 conv 레이어)
-이렇게 만든 FC네트워크는 전체 이미지에 적용.
-FC 네트워크를 적용하기 때문에 crop을 할 필요가 없음.(crop을 사용하면 입력 이미지를 더 세밀하게 샘플링하므로 정확도 향상 가능.)
-crop에 convnet을 적용할 때, 컨볼루션된 특성맵은 제로 패딩이 되지만, dense evaluation의 경우, 패딩이 이미지의 인접 부분에서 자연스럽게 발생함.
3-3. Implementation Details
-다중 GPU 훈련은 데이터 병령 처리를 활용하며, 각 훈련 이미지의 배치를 여러 GPU 배치로 분할하려 각 GPU에서 병렬로 처리함.
-GPU 배치의 그래디언트가 계산된 후, 전체 배치의 그래디언트를 얻기 위해 평균화 함.
-GPU간의 계산은 동기화 되므로 단일 GPU 계산과 일치함.
4. Classification Experiments
-데이터셋: 1000가지 클래스의 이미지를 포함하며 train data(1.3백만), validation data(5만), test data(100만)
-top-1 오류: 잘못 분류된 이미지의 비율
-top-5 오류: 실제 카테고리가 상위 5개 예측 카테고리 밖에 있는 이미지의 비율
4-1. Single Scale Evaluation
-단일 스케일에서 레이어 구성, 정규화를 한 A와 그렇지 않은 A를 비교한 결과 향상시키지 않음. 그래서 깊은 아키텍쳐에서는 정규화를 사용 하지 않음.
-Convnet의 깊이가 증가함에 따라 분류 오류가 감소함,
-스케일 지터링은 고정된 가장 작은 측면의 이미지로 훈련하는 것보다 훨씬 더 나은 결과를 이끌어냄.(스케일 지터링에 의한 훈련세트 보강이 다중 스케일 이미지 통계를 포착하는 데 실제로 도움이 됨을 의미.
-여러 크롭을 사용하는 것이 dense evaluation보다 약간 더 나은 성능을 발휘하며 같이 사용하면 더 우수한 성과를 냄.

4.2 Multi scale Evaluation
-만약 훈련에서 사용된 스케일이 고정된 경우, 지나친 스케일 변환은 top-1 error 상으로 성능이 크게 떨어진다는 것을 확인함.
-test에는 스케일의 변환을 하는 것이 성능 향상에 도움이 된다는 것을 알 수 있음.

4-3. Multi-Crop Evaluation
-다중-크롭 평가와 dense evaluation은 서로 상호 보완적이기 때문에, 같이 합해서 사용하는 것이 좋다.

4-4. ConvNet Fusion
-모델들을 서로 보완하여 성능을 향상 시키며, 최상위 ILSVRC에서도 사용되었음.

4-5. Comparison With The State Of The Art
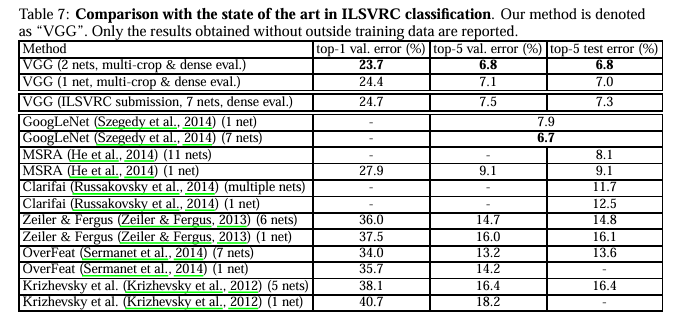
5. Conclusion
-매우 깊은 합성곱 신경망을 평가해본 결과, 표현의 깊이가 분류의 정확도에 유익함. 상당히 증가한 깊이를 갖는 전통적인 ConvNet 아키텍쳐가 매우 좋은 성능을 보여줌.
-시각적 표현에서의 깊이의 중요성을 확인함.