Abstract
깊은 neural network에는 기본적으로 학습을 진행하는데 어려움이 있다는 단점이 있음. 그래서 residual learning frameworks를 제안해서 training의 과정을 더 쉽게 할 수 있도록 함. 이전과는 다르게 훨씬 더 깊은 네트워크를 학습했다는 것이 특징인 것으로, 별도의 residual functions를 학습할 수 있도록 해서 상대적으로 학습이 잘되고 레이어의 깊이까지 더 늘릴 수 있다는 장점이 있음. 이런 방법을 통해 layers를 152개나 늘린 결과 기존의 VGG 보다 더 단순하지만 성능은 올라간 networks를 만들었음. 이는 CIFAR-10에서도 성능의 개선을 보였음. features를 표현하는 데에 있어서 깊이는 컴퓨터 비전의 업무에서 굉장히 중요한 부분인데, resnet은 VGG에 비해서 더 깊게 하는 데에 있어서 별다른 제한이 없고 다양한 대회에서 상위권에 위치할 만큼 비단 이미지분류 뿐만 아니라, 객체 탐지나, 이미지 분할 등 다양한 곳에서도 효과적임.
Introduction
기본적으로 ConvNet를 깊게 쌓는 시도들은 이미지 분류에서 중대한 돌파구를 수행함. 실제로 low/mid/high 레벨의 features들이 적절하게 layer가 깊어짐에 따라서 추출이 됨. 깊어진다는 것은 곧 특징들이 풍부해진다는 것을 뜻하는데, 이는 네트워크의 깊이를 적절히 깊이 설정해서 장점들을 적절히 취할 수 있음. 그렇다면 무작정 레이어를 깊게 쌓으면 되지 않을까? 그렇지 않음. 가장 대표적으로 vanishing/exploding gradient라는 문제점이 있음. 이를 해결하기 위해 가중치값을 초기에 적절히 초기화함으로써 학습이 잘 이뤄지도록 해야함. 본 논문은 degradation문제가 발생할 수 있는데,(깊이가 어느 정도를 넘어가게 되면 오히려 정확도가 낮아짐) 이는 오버피팅을 일으키거나, 트레이닝 에러를 높이는 결과를 초래함. 실제 아래 그림1에서 보면, 무작정 깊게 했을 때, 오히려 오류가 높아지는 것을 볼 수 있음. 이런 것들을 해결하고자 deep residual learning framewworks를 제안함(ResNet) 별도로 residual mapping을 정의하여 더 쉬운 연산을 꾀하는 것, 쉽게 말해서 극단적인 경우(identity mapping이 optimal한 해라고 했을 때) 함수 f가 0이 되도록 하는게 훨씬 쉽다는 것과 같음. 결과적으로 shortcut connection은 identity mapping으로 사용할 수 있음. 이는 별도의 파라미터가 필요하지도 않고 복잡도도 굉장히 낮으며, 구현이 쉽다는 것이 장점. 이러한 ResNet은 깊이가 깊어지면 깊어질수록 정확도가 올라가는 장점을 가지고 있음. 특정 데이터셋이도 국한되지 앙ㄶ는다는 것이 여러개의 대회에서 성능이 좋았다는 것으로 반증됨. >> 충분히 다른 분야들에도 적용 가능함.


2. Related Work
Residual Representations. 본 논문에서는 이런 residual한 테크닉들이 이전부터 많이 사용되었음을 언급중.
Shortcut Connections. 치근 딥러닝 연구에서도 많이 사용되고 있으며 highway networks등 shortcut connection을 사용한 비슷한 논문들도 존재함을 명시중임.
3. Deep Residual Learning
3.1. Residual Learning
h를 optimal한 mapping으로 보았을 때, 여러개의 점진적인 레이어를 학습하는 것으로 이해할 수 있음. 사실 이론적으로 보았을 때, h - x로 볼 수 있는데, 수학적으로는 h를 그대로 학습하는 것과 크게 다르지 않을 수 있음. 다른점은 f로 학습을 할 때, 난이도가 굉장히 낮아진다는 것임. 이게 납득이 가지 않을 수 있고, 직관에 반하는 아이디어일 수 있음. 그러나,추가적으로 더해지는 레이어가 identity mapping이라고 한다면, 깊은 모델이 얕은 모델보다 훈련오차가 크지 않아야 한다는 것을 의미함. 이로 확실하게 알 수 있는 것은 optimal function이 zero mapping 보다 identity mapping에 더 가깝다면, 이는 확실히 residual을 이용하는 것이 학습하기 쉬움을 직관적으로도 이해할 수 있을 것임. residual을 사용하지 않는다면 이전 레이어에서 나온 값인 x를 보존하고, 추가적으로 필요한 정보를 학습하기 때문에, 학습하기가 어렵기 때문.
3.2. Identity Mapping by Shortcuts
함수 y는 입력 x에 대한 함수 f의 출력에 입력 x를 더한 것으로 정의됨. 이때 Wi는 가중치, 즉 컨볼루션 네트워크라, f는 residual mapping을, x는 identity mapping즉, shortcut connection을 의미함. 이러한 구조를 사용함으로써, 모델은 입력과 출력간의 차이를 학습하는 대신, 잔차(residual)를 학습하여 더 효과적인 학습을 이룰 수 있음. 해당 식은 bias를 아예 고려하지 않도록 정의가 된 것임.

이런식으로 shortcut connection을 사용할 때는 추가적인 파라미터가 사용되지 않는 다는 장점이 존재, 공평하게 비교했을 때에도 더욱 우수한 결과를 보였음. 추가적으로, x를 shortcut connection을 통해서 mapping을 시켜줄 때, input과 output의 차원이 다르다고 하면, Ws를 곱해줌으로써 차원을 맞춰줄 수도 있음.

다만 기본적으로 identity mapping을 이용했을 때에도 충분하게 높은 성능을 보일 수 있다고 말하고 있음. 또한 f를 만들 때 wheight 값을 중첩해서 사용하지 않고, single layer로 만들게 되면 하나의 linear layer와 마찬가지이기 때문에 이경우에는 이점이 없음. 그래서 f가 여러개의 weight 값이 중첩된 형태로 사용이 될때 유의미한 효과가 있음.
Plain Network(기본적인 CNN모델임과 동시에 아래 그림에서 가운데 모델). 기본적인 network는 VGG에서 제한되었던 기법들을 적절히 따르고 있는 것을 가지고 와서 비교함. 3x3 필터를 이용하고 output feature map과 사이즈를 같도록 하기 위해서 같은 개수의 filter를 사용하고, feature map의 사이즈가 절반으로 줄어들 때는, filter의 사이즈를 두배로 늘려서 layer마다 time complexity를 보존하도록 네트워크를 구성. 별도의 pooling layer를 사용하지 않고, convolution layer에서 stride를 2로 설정하여 downsampling을 진행. 이후 average pooling 진행 하여 1000개의 클래스를 분류함. 이는 일반적인 VGG모델보다 성능은 좋고 복잡도 또한 낮았음.
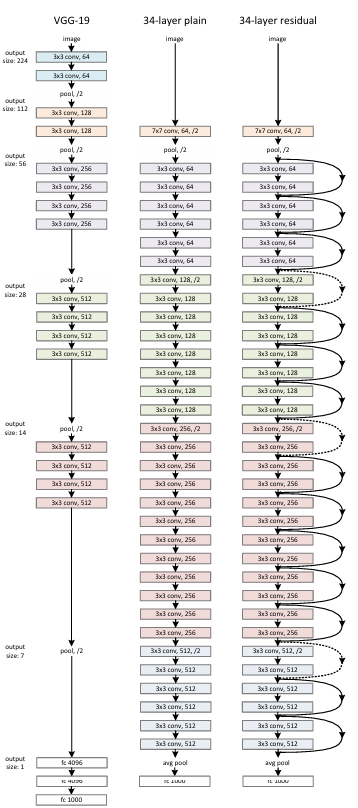
점선으로 표시된 부분은 입력단과 출력단의 차원이 맞지 않아서 차원을 맞춰주도록 하는 기술이 가미된 shortcut connection임. 마지막 3번째 그림은 convolution network를두개씩 묶은 것을 3번 반복하고 크기바꾸고 4번반복 하고 크기바꿔서 6번 반복하고 크기바꾸고 3번 반복하는 구성임. VGG와 비교했을 때, FLOPS는 오히려 감소.(계산 복잡도의 척도임) 입력단과 출력단의 차원이 동일할 때는 그냥 identity mapping 사용, 그렇지 않다면, 1.패딩을 붙여서 identity mapping 수행. 2.projection 연산을 사용한 shortcut connection 사용. 실제 구현상의 테크닉으로는 이미지의 경우, 224 224로 랜덤하게 crop 하거나 horizontal flip를 수행. resnet 같은 경우에는 매 convolution network를 거칠 때마다 배치 정규화를 이용함. 학습률도 점진적으로 줄여나갈 수 있도록 학습을 구성. 또, weight decay 값, momentum 값의 입력을 해서 학습을 진행.
4. Experiments
4.1. ImageNet Classification
2012년에 이미지 분류의 대회에서 128만 트레인 데이터, 5만 validation 데이터 10만 개의 테스트 데이터로 수행.
Plain networks. 얕은 network보다 더 깊은network가 오류율이 높았음.
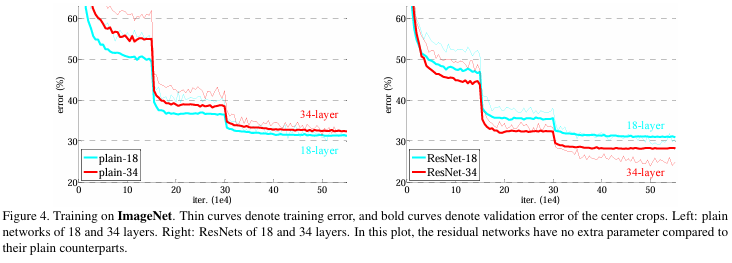

하지만 논문의 저자들은 vanishing gradient의 영향이 아니었다고 주장함. 학습 과정에서 순전파 역전파를 볼때 신호가 사라지는 것이 없었기 때문임. 오히려 그들은 그 이유를 기하급수적으로 낮은 수렵율에 있다고 추측함.
ResNet. 깊어질수록 더 성능이 개선됨. training error 또한 확실하게 줄어들고 일반화 성능 또한 높음. 실제로 수렴속도 또한 빠른 것을 볼 수 있음. 결과적으로 초기 단계에서 더욱 빠르게 수렴할 수 있도록 해줌으로써, 이러한 optimization 자체를 더욱 더 쉽게 만들어주는 것이 장점임. 추가적으로 shortcut connection을 위해서 1)패딩을 한 후, identity mapping을 사용할 지 2)차원이 커질 경우에만 projection을 사용 3)projection을 사용으로 나뉨. 3)의 성능이 가장 높음. 그러나 projection이 필수일 정도는 아님.
Deeper Bottleneck Architecture. 1x1 3x3 1x1의 순서로 필터를 사용하는데 이렇게 작은 커널을 사용함으로써 파라미터가 줄어드는 효과가 있음. 결론은, 이러한 bottleneck design에서는 identity shortcuts이 더 효과적인 모델일 것임.
101-layer and 152-layer ResNets: 더욱 깊어질수록 성능이 좋아졌으며 복잡도 또한 낮아지는 효과를 봤음. 그래서실제로 깊게 쌓은 뒤 앙상블을 했을 때 매우 좋은 성능을 보임.
4.2. CIFAR-10 and Analysis

CIFAR-10에서도 마찬가지로 수행했을 때 layer가 깊어질수록 다른 것들의 파라미터보다 개수도 적고 에러율도 낮아지는 것을 볼 수 있었음.
Analysis of Layer Responses.

기본적으로 ResNet의 경우에 response 값이 상대적으로 작은 것을 볼 수 있음. residual function이 non-resi~보다 더욱더 값이 0이 가까운 형태로 optimization 됨. 또 작은 데이터셋에 대하여 너무 불필요한 수준으로 깊어지면 성능이 떨어질 수 있음.(overfitting)
4.3. Object Detection on PASCAL and MS COCO
ResNet을 object detection과 MS COCO에도 사용한 결과 마찬가지로 AP(Average Precision) 값을 비교한 결과, 기본 VGG에 비해 ResNet이 더 좋은 결과를 보였음.
